Compile 是什么
Compiler 基本原理
最近准备做 Programming Language 方向的研究,所以准备先简单学习一些静态分析相关的知识。而静态分析,很大程度上就是在模拟整个代码编译执行的过程,因此我们需要了解一下编译器 Compiler 是怎么工作的。
编程语言,作为人类创造的一种语言,它必然会包含人类语言的特性。或者说,它的编译过程是符合人类对语言的思考过程的。
本质:读取人类编写的源程序,并通过一系列的规则翻译成一个等价的、机器可读的目标程序。
对用户来讲,编译器就是一个将源语言转换成目标语言的黑盒子。而将这个黑盒子打开来看,我们可以看到它是有一系列的流程来完成的。这里有一个简单的图来进行介绍(不同讲解的编译流程可能有点细微差别,这里我以南京大学课程为主)。**PS:**这里图中黑色部分是主体流程,红色字体是流程的主要分析方法,蓝色字体代表中间数据,红色标签代表主要技术,黄色标签代表举例。

- Scanner:主要完成词法分析(Lexical Analysis)工作,将源代码分割成单个的词素(lexeme)或者记号(Token),并给每个词素或记号赋予相应的类型。
- Parser:主要完成语法分析(Syntax Analysis)工作,将词素序列根据一定的规则转换为抽象语法树(Abstract Syntax Tree, AST),并检查代码是否符合语法规则,并确定代码的结构。AST 是一个树形结构,用于表示代码的语法结构,它将代码转换为一系列的语法分析树节点。
- Type Checker:主要完成语义分析(Semantic Analysis)工作,检查代码的语义是否正确。例如,它会检查变量是否被声明,是否进行了类型转换等。如果代码不符合语义规则,编译器会给出相应的错误信息。
- Translator:将抽象语法树转换成中间表示(Intermediate Representation, IR),即将源代码转换为一系列的指令。中间表示是一种与具体机器无关的代码,常用的是三地址码(3 Address Code, 3AC),
- Code Generator:这个步骤将中间代码转换成目标机器的机器码,即将中间代码转换为一系列的指令,用于实现代码的功能,并且会对代码进行进一步的优化和处理。目标机器码可以理解为是一种可以直接在特定硬件上运行的代码。
后面的章节我们将对这些过程进行逐一讲解。
类比人类语言
简述了 Compiler 的原理后,我们可以将其类比于人类对一种语言的理解过程,我们来举个例子。

首先一句英文我们是如何去理解的呢?我们肯定首先去对他进行词法分析,将其分词后首先判断单词是否存在,接着我们将其转化为token;接着将其进行语法分析转化成一个树状结构来判断是否存在语法上的错误;最后我们在对其语意进行判断即可。当然一句话还可以进行缩写和优化,不过这并不在这部分考虑的范围内啦。
编译型语言 & 解释型语言
编译和解释是当下最常见的两种语言类型,而其概念上的区别想必大多数人都不知道,这里我们从用户的角度来看编译器和解释器是如何处理用户程序的。
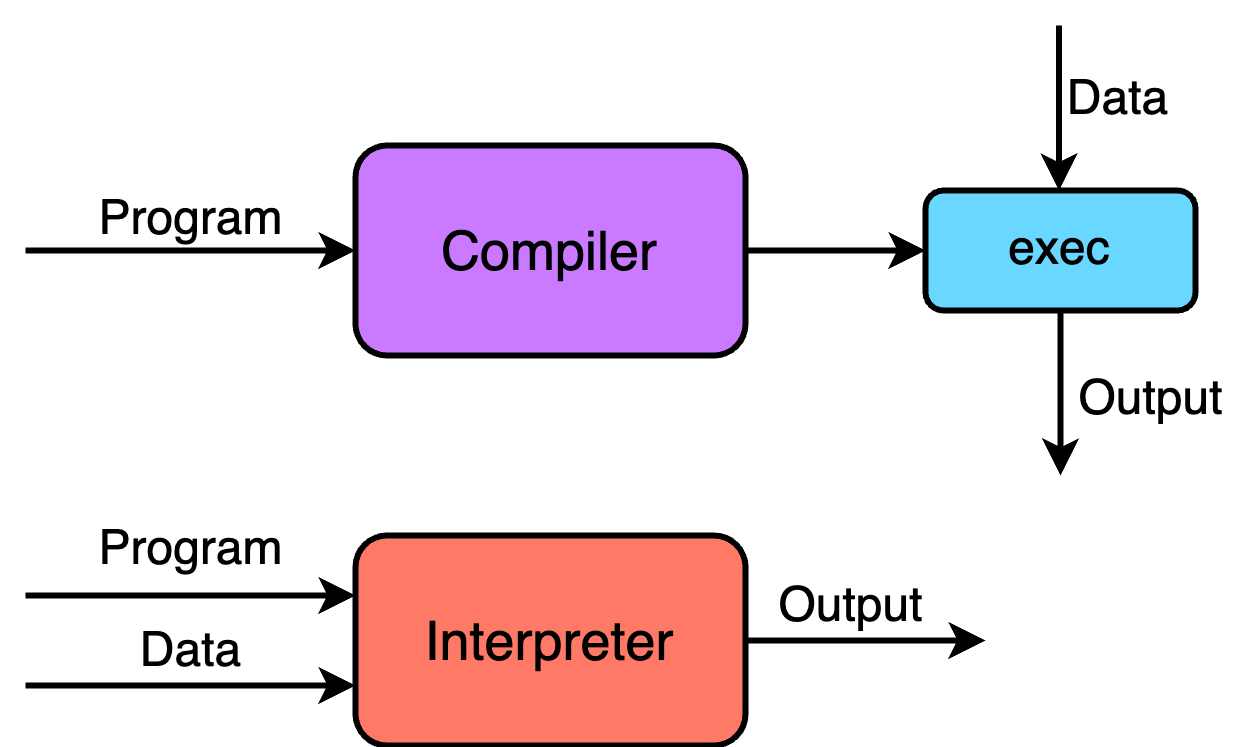
- 编译器读取用户书写的源程序,并将源程序编写成另一种语言编写的目标程序,之后用户给定数据,并调用程序产生输出。
- 解释器并不直接生成目标程序。而是直接利用用户的输入来执行源程序中的指定操作。
这里我们使用一个表格来进行简单的对比:
| 编译型语言 | 解释型语言 | |
|---|---|---|
| 优势 | 编译速度快 | 语言灵活,动态性,程序较小;解释器自己执行源程序,代码本身相对平台独立 |
| 劣势 | 测试前完成整个编译步骤需要额外时间;生成的二进制代码对平台有依赖性 | 执行速度慢 |
| 常见语言 | C、C++、Pascal、Go等 | Java、Python、JavaScript、Ruby、MATLAB等 |
这里需要注意的是,大多数编程语言可以同时具有编译和解释的实现——语言本身不一定是编译或解释的。但是,为简单起见,通常将其简称为某一类。
例如,Python 可以在交互模式下作为编译程序或解释语言执行。另一方面,大多数命令行工具,CLI 和 shells 在理论上可以归类为解释语言。
一个例子
为了更好的用一个例子来理解这两者的区别,我们用一个食谱的例子来进行解释。假设你需要做一道古老的菜(咖喱酱),而这道菜目前只有英语版的食谱,这时候有两个方法。
- 将英语版翻译成中文版。之后我们每次都可以根据这个中文版进行咖喱酱的制作,这就是编译版本。
- 找一个懂英文和中文的人。每次做菜都让这个人看着菜谱给你指导,从而制作咖喱酱,这就是解释版本。